本帖最后由 马猴烧酒 于 2018-8-27 08:47 编辑
本文转载于https://blog.csdn.net/m0_37744293/article/details/77426851 1 简介
我们如何评价一部电影上映之前就判断处着是不是一部伟大的电影?
这位数据集的作者长期被这个问题所困扰,很多人依赖影视评论家来评分电影,也有一些人只凭自己的直觉,但电影上映之后需要过很长时间才会获得合理的影评,同时,人们的直觉有时候是靠不住的。 所以我们提出以下两个问题
1、人类每年拍摄出数以千计的电影,除了依赖影视评论家的直觉,我们有更好的方式来判断出伟大的电影么?
2、电影中海报中的人物和电影评级有关系么?
为了回答这个问题,作者在IMDB爬取了5000多条电影数据,整个爬取过程花费2个小时完成,最后,作者获取了需要的28个特征变量,和来自5043部电影和4906张电影的数据,涵盖66个国家,横跨100年的时间,这里有2399位独特的电影导演,数以千计的男女演员。
28个特征变量如下:
图1-1
- facenumber_in_poster:海报中的人脸数量
- director_name:导演姓名
- movie_title:电影片名。
- director_facebook_likes:脸书上喜欢该导演的人数
- title_year:电影年份
- duration:电影时长
- actor_1_name:男一号姓名
- country:国家
- actor_1_facebook_likes:脸书上喜爱男一号的人数
- genres:电影题材
- color:画面颜色。
- actor_2_name:男二号姓名
- aspect_ratio:画布的比例
- actor_2_facebook_likes:脸书上喜爱男二号的人数
- content_rating:电影分级
- plot_keywords:剧情关键字
- actor_3_name:三号男演员姓名
- language:语言
- actor_3_facebook_likes:脸书上喜爱3号男演员的人数
- budget:制作成本
- cast_total_facebook_likes:脸书上喜爱演员的总人数
- gross:总票房
- movie_facebook_likes:脸书上被点赞的数量
- movie_imdb_link:imdb地址
- imdb_score:imdb上的评分
- num_voted_users:参与投票的用户数量
- num_critic_for_reviews:评论家评论的数量
- num_user_for_reiews: 用户的评论数量
数据分析部分主要以 Python 编程语言为基础,使用 pandas 作为数据整理和统计分析的工具,matplotlib 用于制作图形,再加上Tableau的数据可视化分析。
数据加载- import pandas as pd
- movies_df = pd.read_csv('movie_metadata.csv')
- print(movies_df.head())#默认头5行
- print(movies_df.info())#DataFrame的简明总结
- print(movies_df.describe())#返回count mean std min max等值
数据清洗——去重 - movies_df= movies_df .drop_duplicates()
- print(movies_df.head())#默认头5行
- print(movies_df.info ())
- print(movies_df.describe ())
在pandas中有两个函数是专门用来处理重复值的,分别是duplicated函数、drop_duplicates函数。Duplicated函数用来查找并显示数据表中的重复值。返回一个布尔值的Series.drop_duplicates()表示将过滤重复行,即“去重”,默认是判断全部列。当然也可以指定判断某一列是否有重复,该列中重复的数据就删除该数据整行。duplicated函数、drop_duplicates函数默认保留的是第一个出现的值的组合。传入take_last=True则保留最后一个。
数据清洗——处理缺失值 - movies_df = movies_df .dropna()
地域性分析: - grouped = movies_df.groupby('country').size()
- print(grouped.sort_values( ascending=False ).head(10))#按照值排序
- print(grouped.sort_index())#按照索引排序
- import matplotlib.pyplot as plt
- grouped = movies_df.groupby('country').size()
- grouped_head_10=grouped.sort_values( ascending=False ).head(10)
- print(grouped_head_10)#按照值排序
- print(grouped.sort_index())#按照索引排序
- grouped.plot(kind = 'bar')
- plt.show()
- grouped_head_10.plot(kind = 'bar')
- plt.show()
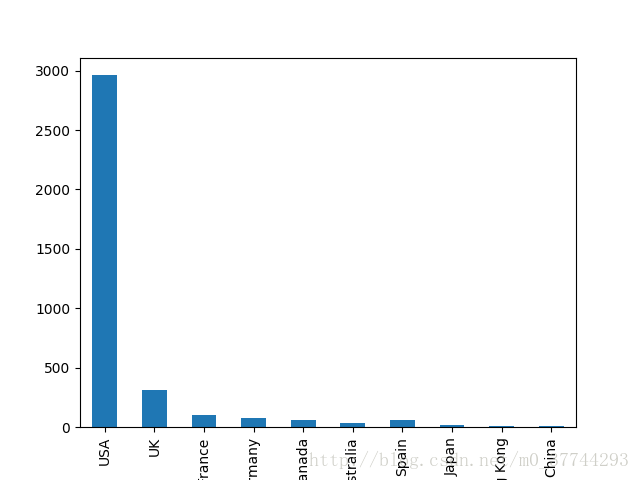
图2-1 综上可见,美国以3773的优势取得第一,英国443位居第二,法国154位居第三,中国位居第九。 高质量电影分布 前10名高质量电影的国家和具体数量 - movie_max=movies_df['imdb_score'].sort_values(ascending=False).head(10)
- print(pd.Index(movie_max ))
- movie_max1=movies_df.sort_values(['imdb_score'],ascending=False).head(10)
- #print(pd.Index(movie_max1 ))
- print(movie_max1)
- print(movie_max1[['movie_title','imdb_score']])
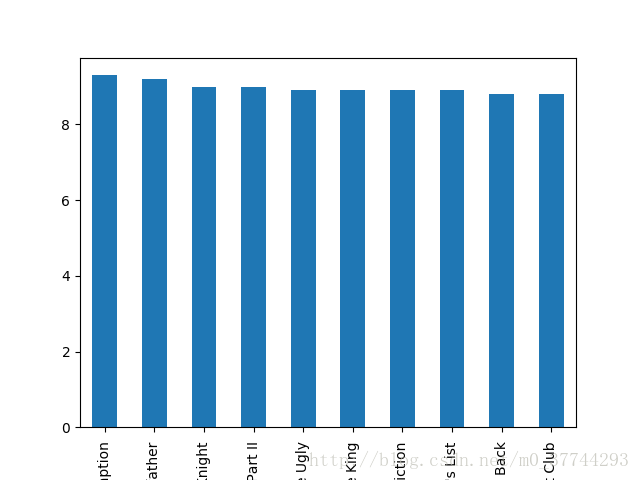
运行结果 - movie_title imdb_score
- 1937 The Shawshank Redemption 9.3
- 3466 The Godfather 9.2
- 66 The Dark Knight 9.0
- 2837 The Godfather: Part II 9.0
- 4498 The Good, the Bad and the Ugly 8.9
- 339 The Lord of the Rings: The Return of the King 8.9
- 3355 Pulp Fiction 8.9
- 1874 Schindler's List 8.9
- 2051 Star Wars: Episode V - The Empire Strikes Back 8.8
- 683 Fight Club 8.8
- movie_max_series=pd.Series(movie_max['imdb_score'].values,index = movie_max['movie_title'])
- print(movie_max_series)
- movie_max_series.plot(kind='bar')
- plt.show()
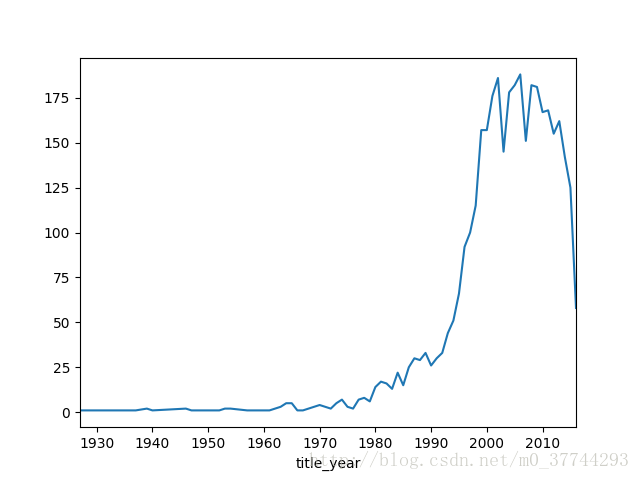
- grouped_year= movies_df.groupby('title_year').size()
- print(grouped_year)
- grouped_year.plot()
- plt.show()
图2-3
| 




 发表于 2018-8-24 17:50:56
发表于 2018-8-24 17:50:56