|
这是一篇iccv19的oral paper,直到2020年一月作者才放出来,代码已经开源,用于视频分割。 摘要这篇工作提出了一种新颖的注意力图神经网络,用于零样本视频目标分割(vos)。本文提出的AGNN将vos任务转化为在视频图上迭代的信息融合的过程。具体来说,Agnn建立了一张全连接的图,图的节点由视频帧构成,图的边由任意两个帧的关系构成。这种关系用一种可微的注意力机制描述。Agnn能够充分捕捉视频帧之间丰富且高级语义联系。作者在文中为了证明agnn的泛化性,将agnn扩展用于新的视觉任务:ICOS。广泛的实验证明Agnn可以学习视频帧之间潜在的语义和形象信息,同时检测到这些帧出现的共同的目标。 引言自动检测出在一个视频中主要的目标是一个困难问题,同时也对很多应用有益,比如省去了人为对视频编辑的操作。然而,在不了解前景目标的先验知识的情况下,想要检测出视频中占主体的目标是很困难的挑战任务。现存的一些传统方法,往往利用动作边界,显著性检测,或者轨迹,光流等信息捕捉长时动作信息。最近有一些基于深度学习的方法,用大规模训练数据训练网络,在test过程,产生了零样本的方案。它们大部分都是应用了双流结构,结合了局部动作和形象信息,并且应用了RNN来建模一帧一帧之间的动态信息。 上面的所以方法推动了vos领域的发展,获得了越来越好的指标,但同时有两点限制。第一,它们主要关注后续帧中局部配对或者后续的关联,却忽视了帧之间普遍存在的高阶联系。第二,因为它们未能充分利用丰富的关系,它们不能完全地捕捉视频内容,因此容易得到错误的前景估计。从另一个角度讲,因为视频目标经常存在遮挡,巨大的尺度变化和形象变化,推理出前景目标是很难的,如果仅考虑局部配对关系。 为此,作者提出agnn,一种注意力图神经网络,解决零样本视频目标分割。具体地,建立一张图,图的节点是视频的每一帧,边代表两个节点的联系,该图是完全图,即每一个节点都和其他所有节点都有边连接。边的衡量方式是用一种注意力机制来表示。如下图所示
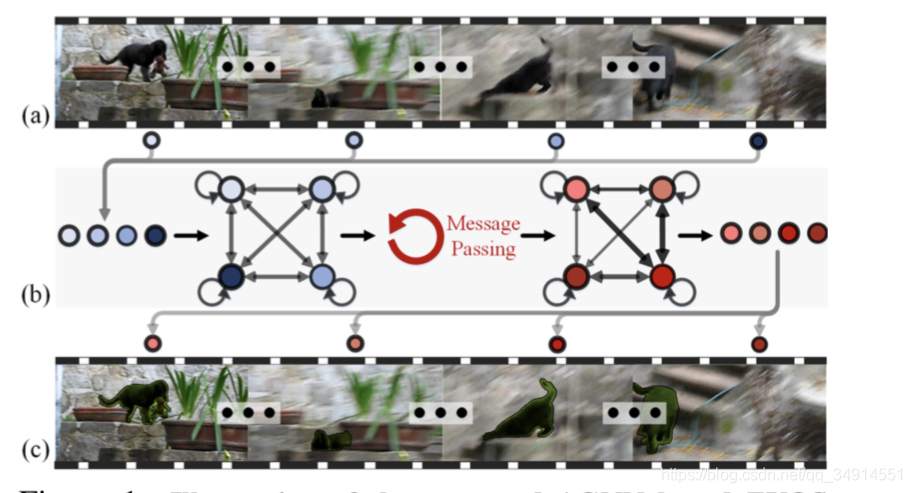 图a是视频帧原图,b是pipeline示意图,每个帧都是一个节点,节点都其他节点都有边,甚至还有一个边与自己相连。经过迭代的信息传递,前景目标的估计从全局角度获得。 Agnn在多个帧上,天然具有数据增强的效果,因为样本帧的组合方式是巨大的。由于递归特性,agnn可以处理可变的节点数目,可以增添输入节点以此获得更高的性能。值得一提的是,Agnn是第一个应用gnn来解决vos任务的工作,为vos任务带来新的思路。 方法gnn的通常表达式一行图用G(V,E)表示,v i i n V v_i \ in Vvi inV ,V代表顶点集合,E代表边集合。边集合往往用一个矩阵表示,e i , j e_{i,j}ei,j代表从节点i ii到节点j jj的边。
对于节点v i v_ivi,gnn学习一个能更新的节点表征h i h_ihi,然后由h i h_ihi产生o i o_ioi,作为第i个节点的label。具体来说分两步,第一步是带参数的信息传递过程,递归运行K次。在第k次迭代中,对于节点v i v_ivi,其状态更新根据m i k m_i^kmik和之前的状态h i k − 1 h_i^{k-1}hik−1,
信息聚合,从邻域处累加信息,
 不过gnn不能保持空间结构,作者提出agnn,和一个注意力机制描述边。 agnn每个帧的特征就视为一个node,用deeplabv3得到。
所以节点的初始状态为
h i 0 = F d e e p l a b ( I i ) h_i^0=F_{deeplab(I_i)}hi0=Fdeeplab(Ii)
按照前文描述,需要迭代k次才能得到最终状态。每一次迭代需要边信息。在有向图h中,连接两个节点的边有两种,e i , j e_{i,j}ei,j是从i到j的边,e j , i e_{j,i}ej,i是从j到i。还有一种特别的边是e i , i e_{i,i}ei,i是从i到自身。
第k个状态的边e i , i k e_{i,i}^kei,ik使用自注意力计算。
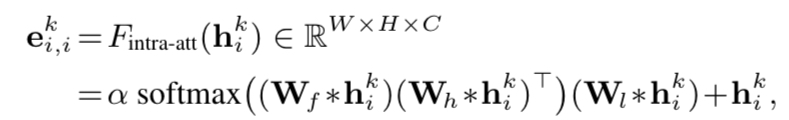
i到j和j到i的边,使用下面的公式计算
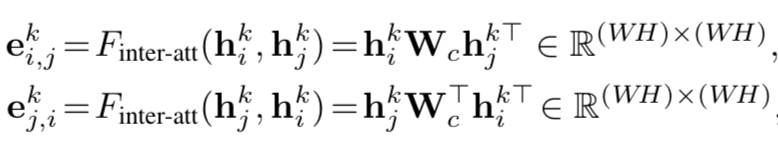
W c ∈ R C × C W_c \in R^{C \times C}Wc∈RC×C是一个参数矩阵 消息聚合从状态k-1到状态k跳变,需要两步,第一步就是消息聚合,即第i个节点要接受来自邻域节点的信息,聚合在第i个节点上。
m i , i k m_{i,i}^kmi,ik指的是自己对自己的影响,就用k-1的自环边e i , i k − 1 e_{i,i}^{k-1}ei,ik−1表示.
m j , i k = s o f t m a x ( e i , j k − 1 ) h j k − 1 m_{j,i}^k=softmax(e_{i,j}^{k-1})h_j^{k-1}mj,ik=softmax(ei,jk−1)hjk−1 这里计算j到i的message,为啥不用j到i的边,却用i到j的边,这是看论文不懂的一点,作者也没有回复我。
作者避免有些帧的质量差,从而引入噪声,还用到了gated conv,
第k状态,第i节点的信息表示为:
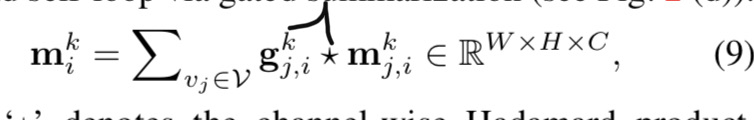
相当于其他位置的节点都往i节点送信息。然后加权求和,权重由gated conv学习。 最终状态我们得到信息聚合之后,就可以求第k状态的第i个节点的状态了。
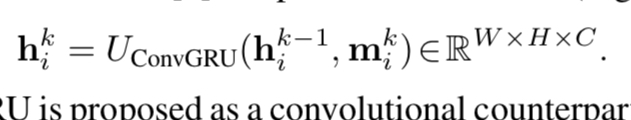
作者用了convgru层。 预测mask得到第k次最终状态之后,就可以由h i k h_i^khik得到s ^ i \hat{s}_is^i 网络结构细节一个视频很多帧,这些帧都一次性创建节点,对gpu的现存要求很大。作者每次训练只随机采样3帧。测试是采样6帧。
损失函数使用weighted bce。backbone使用deeplabv3的前5个阶段。使用显著性检测数据集先预训练backbone。
在多目标分割数据集上,先使用agnn得到视频中的主要目标(primary object),然后使用mask rcnn得到目标的mask proposal。用agnn的结果过滤背景proposal。用iou来连接不同帧的相同目标
| 




 发表于 2020-12-1 09:16:06
发表于 2020-12-1 09:16:06
 楼主
楼主