|
首先对通用行为识别算法做一个初步的了解,之后对通用行为识别进行了简单的分类举例。目的是为之后学习各个行为识别算法做铺垫~~~~~ 本文目录:一.行为识别背景 二.行为识别总结 三.接下来的安排 四.一些心得总结 本文声明:1.写该总结的初衷在于学习和记录,如有侵权,私聊我修改。 2.水平有限,不足之处感谢指出。 3.如有想法,欢迎讨论;如有收获,感谢收藏点赞;没有时间看的同学欢迎收藏mark;欢迎关注专栏,我将持续更新~~ 欢迎讨论,批评指正 呀呀呀
推荐阅读:一文了解关键点检测(姿态估计) 凡心所向素履所往:人体关键点检测(姿态估计)简介+分类汇总zhuanlan.zhihu.com一文了解目标检测 凡心所向素履所往:two/one-stage,anchor-based/free目标检测发展及总结:一文了解目标检测zhuanlan.zhihu.com
一.背景行为识别Action Recognition是指对视频中人的行为动作进行识别,即读懂视频。根据要处理的动作类别和真正要处理的任务不同,在各种情况下所说的行为识别的任务略有差异,首先对两组概念进行对比和区分: 1.Hand gesture, Action, ActivityHand gesture:集中于处理视频片段中单人的手势 Action:短时间的行为动作,场景往往是短视频片段的单人行为,比如Throw,catch,clap等 Activity:持续时间较长的行为,场景往往是较长视频中的单人或多人行为,例如Reading a book,making a phone call, eating, talking to each other, hugging,palying basketball等 这里提一句,Action和Activity的主要区别在于Action是指动作,Activity是指行为,可以认为Action的粒度更细,而Activity的粒度更粗,也可以说Action是Activity的子集。但其实在实际的算法中,有时候也没必要将二者完全区分开。 2.Classification,DetectionClassification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 我们这里所涉及到的行为识别Action Recignition可能是Hand gesture/Action/Activity和Classification/Detection任意组合情况,不做太绝对的区分。但是通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 二.Action Recognition总结1.数据集按照数据集是否包含深度信息,可以将行为识别数据集分为RGB和RGBD两类,我们这里只讨论RGB数据集: (1)UCF-101 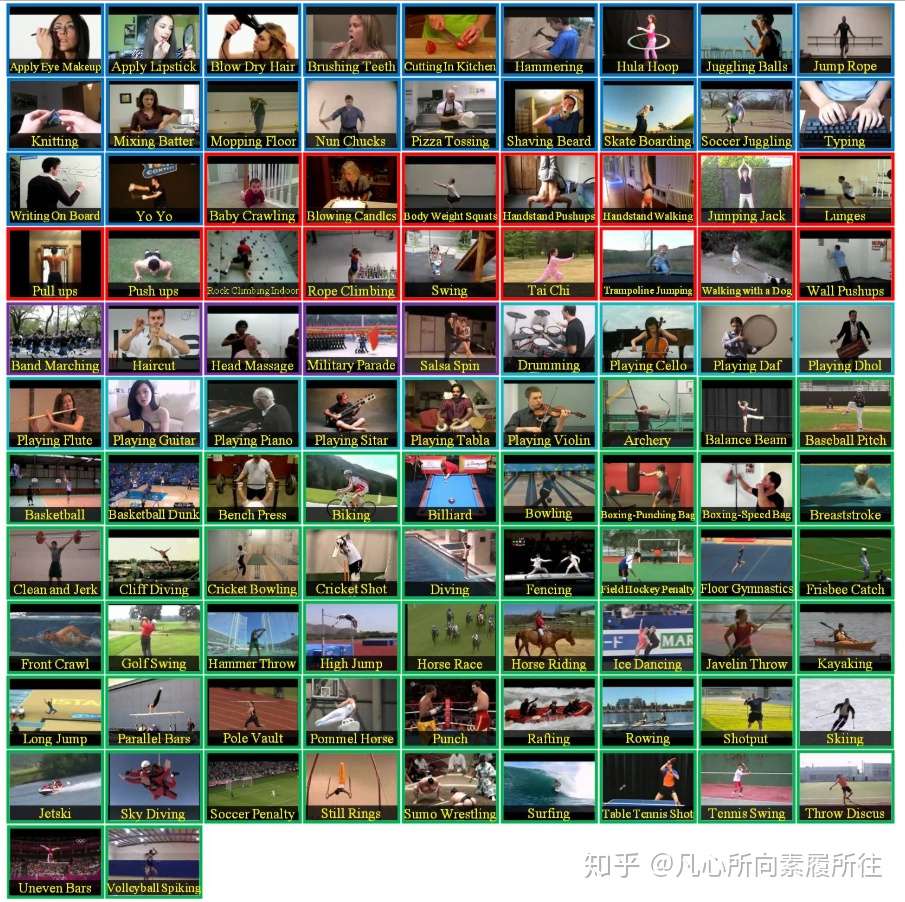 UCF-101是目前行为识别最常使用的数据集之一,共包含101个动作,13320个视频。 该数据集可以分为5大类: ·人物交互Human-Object Interaction ·人体动作Body-Motion Only ·人人交互Human-Human Interaction ·乐器演奏Playing Musical Instruments ·体育运动Sports (2)HMDB-51 HMDB-51共51个识别类别(每个类别至少101个视频片段),6849个短视频,数据来源包含电影,公开数据集,YouTube视频等等。 该数据集可以分为五个大类: ·常见面部动作(smile,laugh,chew,talk) ·复杂面部动作(smoke,eat,drink) ·常见肢体动作(climb,dive,jump) ·复杂肢体动作(brush hair,catch,draw sword) ·多人交互动作(hug,kiss,shake) (3)Kinetics-700 详细说明了UCF101和HMDB51两个数据集,其他数据集只贴上下载地址: (4)Moments in Time(339) (7)Something-Something 2.传统模型在传统的行为识别模型中,通常都是先提取手工特征(HOG,HOF,Dense Trajectories等),然后使用分类器进行分类,iDT是传统方法中最经典、最优的模型,iDT的主要论文包括《Dense Trajectories and Motion Boundary Descriptors for Action Recognition》和《Action Recognition with Improved Trajectories》。 DT算法和iDT算法的基本框架如下图所示,框架包括密集采样点特征、特征点轨迹跟踪和基于轨迹的特征提取三部分,后续再进行特征编码和分类。 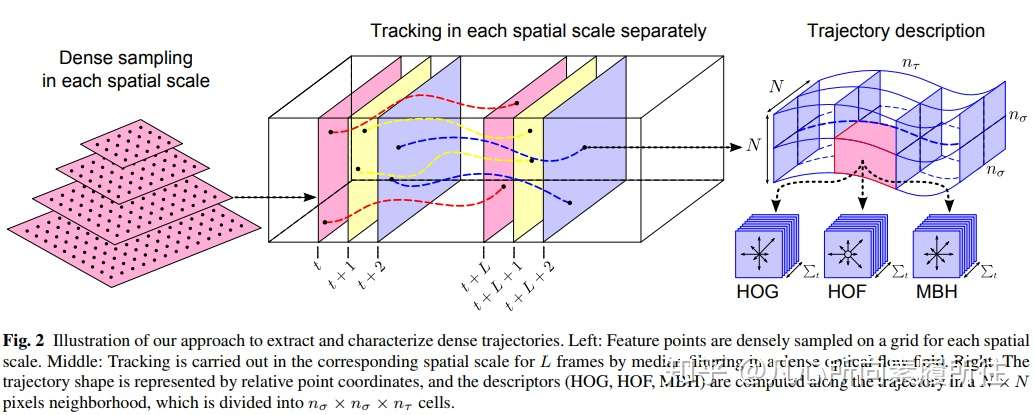 3.基于深度学习的模型 3.基于深度学习的模型按照是否先检测人体关键点,基于深度学习的方法可以简单地划分为“skeleton-based”和“video-based”两类。 (1)skeleton-based的代表性算法包含ST-NBNN,Deformable Pose Traversal Convolution,以及最近比较火热的图卷积方法(例如ST-GCN)。 video-based方法包含几种主流的方法: (2)TwoStream TwoStream将动作识别中的特征提取分为两个分支,一个是RGB分支提取空间特征,另一个是光流分支提取时间上的光流特征,最后结合两种特征进行动作识别,代表性方法如TwoStreamCNN及其扩展,TSN,TRN等。 (3)C3D 3D convolution 直接将2D卷积扩展到3D(添加了时间维度),直接提取包含时间和空间两方面的特征,这一类也是目前做的比较多的topic。代表方法如开山之作C3D及其之后的扩展P3D,R(2+1)D,ECO等,最近FAIR提出了SlowFast算法,CVPR2019上也有相关的论文(比如MARS) 。 (4)LSTM 这种方法通常使用CNN提取空间特征,使用RNN(如LSTM)提取时序特征,进行行为识别。代表方法如CVPR2015的LRCN,但我暂时没有找到特别有代表性的新论文。 综上,行为分析初步了解的总结如下图所示: 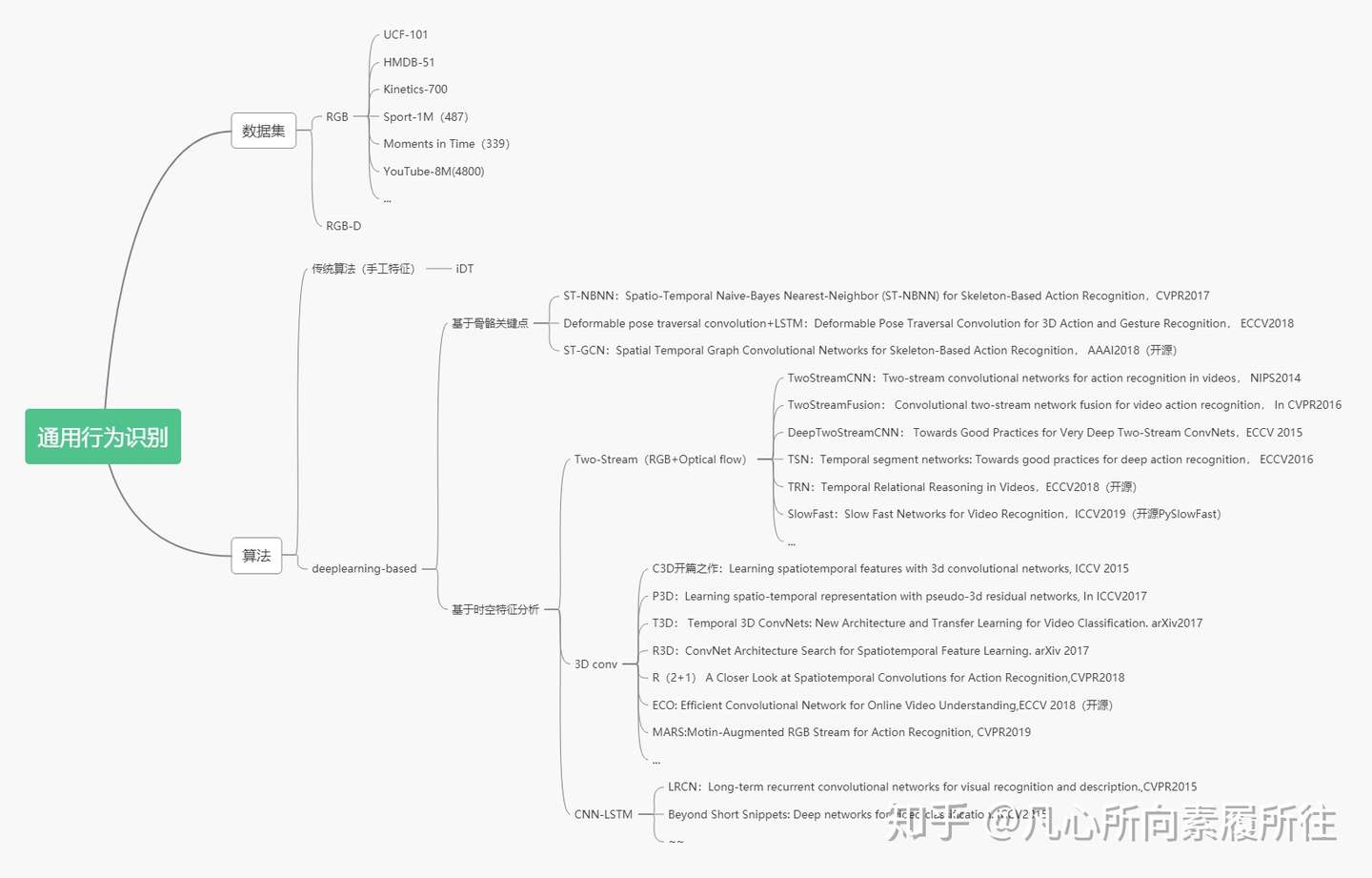 通用行为识别分类总结 通用行为识别分类总结需要说明一下,图中SlowFast模型暂时划分为Two-Stream方法,但它和其他的Two-Stream方法在本质上是不一样的,准确地说它是Two-Pathway的方法(帧率快慢Fast+Slow pathway),而不是Two-Stream的RGB+光流思路。 这里只是对通用行为识别的算法进行了简单的分类和举例,每个类别仍有大量算法未罗列。总的来说多个分支都有最新研究出现,但是相对的基于骨架的图卷积方法和基于视频的3D conv方法更多一些。 至此,对行为识别的初步了解和分类总结告一段落,接下来我会单独写笔记来总结基于深度学习的行为识别中的一些经典论文和最新论文,并对开源代码进行学习和总结,感兴趣的欢迎关注,方便之后的阅读讨论~~~~~ 三.接下来的安排接下来,我将从每一类行为识别算法中挑选经典算法和最新算法进行学习、总结,并对开源代码进行实践~~接下来安排的目录(会不断添加完善)如下,感兴趣的欢迎点赞关注,移步对应论文进行讨论: 1、介绍与综述1.1 行为识别算法初步了解及分类(本文) 1.2 行为识别算法综述类 论文(1) 1.3 行为识别算法综述类 论文(2) 2、Skeleton-based行为识别2.1 Skeleton-based行为识别之 ST-NBNN:Spatio-Temporal Naive-Bayes Nearest-Neighbor (ST-NBNN) for Skeleton-Based Action Recognition 2017cvpr 2.2 Skeleton-based行为识别之 Deformable pose traversal convolution+LSTM eformable Pose Traversal Convolution for 3D Action and Gesture Recognition 2018ECCV eformable Pose Traversal Convolution for 3D Action and Gesture Recognition 2018ECCV 2.3 Skeleton-based图卷积行为识别之 ST-GCN:Spatial Temporal Graph Convolutional Networks for Skeleton Based Action Recognition AAAI2018(开源) 2.4 待续~~~ 3、Two-Stream行为识别3.1 TwoStream行为识别之 TwoStreamCNN:Two-stream convolutional networks for action recognition in videos. In NIPS 2014 3.2 TwoStream行为识别之 TSN: Temporal segment networks: Towards good practices for deep action recognition. ECCV 2016 3.3 TwoStream行为识别之 TRN:Temporal Relational Reasoning in Videos. ECCV2018(开源) 3.4 Two Pathway行为识别之 SlowFast:SlowFast Networks for Video Recognition. ICCV2019 (开源) 4、3D Conv行为识别4.1 3D Conv行为识别之 C3D开篇之作: Learning spatiotemporal features with 3d convolutional networks. ICCV2015 4.2 3D Conv行为识别之 P3D: Learning spatio-temporal representation with pseudo-3d residual networks. In ICCV2017 4.3 3D Conv行为识别之 R(2+1)D:A Closer Look at Spatiotemporal Convolutions for Action Recognition. CVPR2018 4.4 3D Conv行为识别之 ECO: Efficient Convolutional Network for Online Video Understanding. ECCV2018(开源) 4.5 3D Conv行为识别之 MARS: Motion-Augmented RGB Stream for Action Recognition.CVPR2019 4.6 待续~~ 5、LSTM行为识别5.1 LSTM行为识别之LRCN:Long-term recurrent convolutional networks for visual recognition and description. CVPR2015
四.一些零碎的心得总结看了一些论文后,对行为识别有了一些零碎的心得体会: (1)按照使用的数据集类型不同,行为识别可以分为 RGB行为识别 和 基于骨架的行为识别Skeleton-Based Action Recognition 其中RGB的行为识别做的更多一些,应用也更广泛、更直接。 基于骨架的行为识别以特殊的传感器或者姿态估计(关键点检测)算法的结果为输入,进行行为识别。骨架的信息使得行为识别的准确性得到提升,但对输入的要求比较严格(比如现在的业务是接收视频,进行行为识别,就需要先对视频数据进行预处理得到骨架数据,才能应用该类算法,所以感觉在业务上的使用可能不太容易)。另外基于骨架的行为识别目前基本都是在用图卷积GCN来做,数据集基本上就是Kinetics、NTU-RGB D、NTU-RGB D120。 (2)RGB行为识别目前的主流基本上就是Two-Stream和3D conv的方法 总的来说Two-Stream方法一个分支计算空间特征,一个分支用光流计算运动特征,最后整合进行行为识别。 3D Conv方法算是比较端到端的方法,目前都是很多2DConv的一些扩展,在行为识别上表现也不错。 (3)~~~~
重要的参考: (0)俞刚icip 幻灯片 其他了解的参考:
| 




 发表于 2020-12-1 09:08:56
发表于 2020-12-1 09:08:56
 楼主
楼主