|
本文是对论文《SlowFast Networks for Video Recognition》学习时所做的记录和总结. 论文:时间:2019.10.29 作者团队:FAIR(何恺明..)ICCV2019,2019 年 CVPR ActivityNet Challenge Winner 分类:计算机视觉--视频行为识别--两分路C3D
写到这里的时候,默默流下了眼泪,大神也太nb了吧,哭了哭了。。。。 项目:参考: 本文目录:一.论文翻译 二.论文总结 三.论文创新 四.代码实践 本文声明:1.写该总结的初衷在于学习和记录,如有侵权,私聊我修改。 2.水平有限,不足之处感谢指出。 3.如有想法,欢迎讨论;如有收获,感谢收藏点赞;没有时间看的同学欢迎收藏mark;欢迎关注专栏,我将持续更新~~ 推荐阅读:[color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]凡心所向素履所往:人体关键点检测(姿态估计)简介+分类汇总zhuanlan.zhihu.com [color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]凡心所向素履所往:two/one-stage,anchor-based/free目标检测发展及总结:一文了解目标检测zhuanlan.zhihu.com [color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]凡心所向素履所往:two/one-stage,anchor-based/free目标检测发展及总结:一文了解目标检测zhuanlan.zhihu.com [color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]凡心所向素履所往:一文了解通用行为识别ActionRecognition:了解及分类zhuanlan.zhihu.com [color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]凡心所向素履所往:一文了解通用行为识别ActionRecognition:了解及分类zhuanlan.zhihu.com  朋友们路过点个赞吧。。只收藏不点赞 我看不见的。。点赞越多更新越快 朋友们路过点个赞吧。。只收藏不点赞 我看不见的。。点赞越多更新越快
一.论文翻译Abstract: 我们提出了SlowFast网络用于视频识别,我们的模型包含两部分 (1)一个低帧率运行的Slow pathway,用来捕获空间语义信息。 (2)一个高帧率运行的Fast pathway,以精细的时间分辨率捕获运动信息。 通过减少通道容量把Fast pathway设计的非常轻量级,但可以学习到有用的时域信息用于视频识别。我们的模型在视频action classification和detection上都取得了strong表现,且我们的SlowFast概念明确指出了重大改进之处。我们的模型在主要的视频识别benchmarks(包括Kinetics, Charades和AVA)上都取去了SOTA精度。代码开源~ 1.Introduction 在识别图像I(x,y)的时候通常会对称地symmetrically处理两个空间维度x和y, 自然图像的统计分析能够验证这种操作的合理性:自然图像的统计量是近似于一阶同向性的,即所有方向都是同等可能且位移不变的[41,26]。但是对于视频信号I(x,y,t)呢?运动是方向的时空对应counterpart[2],但是并非所有的时空方向都是一样的。慢速运动比快速运动更有可能发生(实际上大多数情况下我们看到的世界都在特定的时刻处于静止状态)且这一点已经在贝叶斯方法中得到了应用:人们如何看待运动刺激[58]。例如,如果我们看到一个孤立的运动边(moving edge),我们会认为perceive它是垂直于自身移动的,即使原则上它也可以具有与自身相切的任意运动分量(光流中的孔径问题the aperture problem in optical flow)。如果实现知道更喜欢慢速运动,那这种感觉是合理的。 如果所有的时空方向都不一样,那么我们就没有理由对称地处理时间和空间(而这正是基于时空卷积的视频识别方法[49,5]所默认的)。相反,我们可以分解factor结构,分别处理空间结构和时间事件events,更具体地,让我们在识别场景下来研究。视觉内容的类别空间语义通常都进展的很缓慢evolve slowly。例如,挥手的时候手还是手,identity不会变化;即使一个人从walking动作变为running动作,人的类别也永远是“人”。所以可以相对缓慢地更新refresh类别语义识别结果(以及颜色,纹理,亮度等)。另一方面,所进行的运动motion可能比其所属的主体身份的变化要快的多,例如拍手、挥手、握手、步行或者跳跃。所以可能要使用快速更新帧(高的时间分辨率)来有效地建模可能快速变化的运动情况。 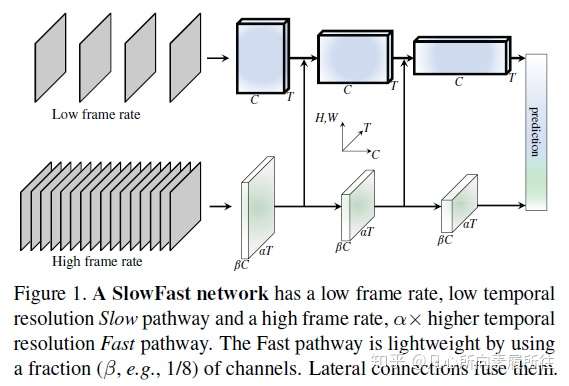 图1. SlowFast模型结构示意图 图1. SlowFast模型结构示意图基于这个直觉,我们提出了一种用于视频识别的two-pathway SlowFast模型(图1)。一个分支用来捕获图像或稀疏帧所提供的语义信息,它以较低的帧率和较慢的刷新速度运行;另一个分支负责快速捕获运动的变化,它以较快的更新速度和高时间分辨率运行,尽管它的时间分辨率很高,但这个分支仍然非常轻量级,大约占整个计算量的20% .这是因为这个分支具有较少的通道数和较弱的空间信息处理能力,而这些信息可以由第一个分支以较少的冗余来提供。我们把第一个分支和第二个分支分别称为Slow Pathway和 Fast pathway,然后这两个分支通过侧向连接lateral connections进行融合。 我们的概念idea使我们的视频模型设计变得灵活有效,由于Fast pathway轻量级的特性,它不需要执行任何的时间池化,它可以高帧率地执行所有中间层并维持时间保真度temporal fidelity;同时,由于Slow pathway的时间速度较低,它可以更加专注于空间域信息和语义信息。通过以不同的时间速率temporal rates处理原始视频,我们的方法允许这两个分支有它们自己的视频建模知识。 还有另一种众所周知的视频识别结构two-stream设计[44],但这和我们的结构在概念上是不同的: (1)Two-Stream方法没有探索不同时间速率的潜力,而这是我们方法的核心观点。 (2)Two-Stream方法的两个streams都使用相同的backbone结构,然而我们的Fast pathway更轻量级。 (3)我们的方法不需要计算光流,因此可以端到端从原始数据学习。 实验发现我们的网络更有效。 我们的方法在一定程度上受到了对灵长类动物视觉系统中视网膜神经元细胞的生物学研究的启发[27,37,8,14,51],虽然这种类比是粗糙且为时过早的。这些研究发现在这些细胞中,大约80%是细小细胞(Parvocellular,P-cells),大约15~20%是磁性细胞(Magnocellular,M-cells),其中M-cells以较高的时间频率运行,并对快速的时间变化做出响应,但是它们对空间细节和颜色不太敏感 -cells可以提供良好的空间细节和颜色,但时间分辨率较低,对刺激的反应比较缓慢。我们的框架和这个研究现象类似: -cells可以提供良好的空间细节和颜色,但时间分辨率较低,对刺激的反应比较缓慢。我们的框架和这个研究现象类似: (i)我们的模型有两个pathway,分别以low和high时间分辨率工作。 (ii)Fast pathway用来捕获快速变化的运动,但只能得到很少的空间细节,类似于M-cells。 (iii)Fast pathway是轻量级的,类似于M-cells那样只占很小的比例。 我们希望这些关系能够激发出更多的用于视频识别的计算机视觉模型。 我们在Kinetics-400,Kinetics-600,Charades和AVA数据集上评估了我们的方法,并在Kinetics动作分类上进行了详尽的消融实验,证明了SlowFast的有效性。SlowFast网络在所有数据集上都达到了新的SOTA,与文献中的先前系统相比有了显著提升。 2.Related Work 时空滤波器Spatiotemporal filtering。可以将动作Action表述为时空目标,并通过时空中的定向滤波来捕获其特征,如HOG3D[31]和cuboids[10]那样。3D卷积网络[48,49,5]将2D图像模型[32,45,47,24]扩展到了时空域,使用相同的方式同时处理空间和时间维度。还有一些方法侧重于进行长时滤波,并使用带有时间strides的池化[52,13,55,62],或者将卷积分解为单独的2D空间和1D时间滤波器[12,50,61,39]。 除了时空滤波或其可分离版本之外,我们的工作还使用两种不同的时间速率来追求时空建模专业知识的更彻底分离。 视频识别中的光流。另一个经典的研究分支致力于构建基于光流的手工时空特征,其中包括光流直方图[33],运动边界直方图[6]和轨迹53]等,它们在深度学习盛行之前就已经表现出了动作识别方面的竞争性优势。 在深度神经网络的背景下,这种two-stream方法[44]通过将光流作为另一种输入形式来利用光流信息。在文献[12,13,55]中,这种方法已经成为许多竞争性结果的基础。然而,光流是手工设计的特征,其在方法学上并不能令人满意,且这种two-stream方法通常由于光流的影响无法端到端学习。 3.SlowFast Network SlowFast网络算是一个以两种不同的帧率运行的单流结构,但我们使用pathways的概念来反应该网络与M-cell、P-cell的类比。我们的SlowFast通用结构包含使用横向连接融合的Slow pathway(3.1节)和Fast pathway(3.2节)两部分,如图1所示。 3.1 Slow pathway Slow pathway可以是任意一个将视频片段作为时空立方体输入的卷积模型(例如[12,49,5,56])。我们的Slow pathway的关键理念是:输入视频帧的时间跨度stride τ很大,也就是说每τ帧才处理一帧。我们研究的典型τ值为16,也就是说对于30fps的视频,slow pathway每秒大约采样处理两帧。将slow pathway采样处理的帧数表示为T,那么原始视频片段的长度就是T×τ帧。 3.2 Fast pathway Fast pathway是一个具有以下特性的另一个卷积模型(与Slow pathway平行)。 High frame rate高帧率。我们Fast pathway的目标是在时间维度上有一个很好的表示,Fast分支的时间跨度是τ/α(其中α是快慢分支的帧率比,α >1),显然Fast分支的时间跨度stride比Slow分支要小。这两个分支在相同的原始视频片段上执行,所以Fast分支处理的帧数就是αT,比Slow分支密集了α倍,我们实验中的典型值为α=8. α的存在是SlowFast概念的关键所在(图1的时间轴),它明确表明了两个路径以不同的时间速度工作,从而驱动了两个子网(两个路径的实例化网络)的专业知识expertise。 High temporal resolution features。我们的Fast路径不仅输入时间分辨率很高,而且在整个网络层级中都追求高时间分辨率特征。在我们的实例中,在整个Fast路径里我们都没有使用任何的时间下采样层(没用时间池化temporal pooling也没有时间跨度的卷积time-strided convolutions),直到最后的分类之前才使用了全局的池化层。这样,我们的特征张量在时间维度上就能始终保持αT帧,尽可能地保持时间保真度。 Low channel capacity。我们的快速路径可以使用很低的通道数来实现SlowFast模型的良好精度(这也是和现存其他模型的一个区别),这使得网络可以轻量级。简言之,我们的Fast路径是一个与Slow路径类似的卷积网络,但其通道数是Slow路径的β倍(β<1),我们实验中的典型值为β=1/8。注意一个普通层的计算量(FLOPs)往往是通道缩放率的平方,这就是Fast路径比Slow路径计算效率高的多的原因。在我们的实例中,Fast路径大概占总计算量的20%左右。有趣的是,第一节中提到过动物视觉系统中的15~20%细胞是M-cells(对快速运动很敏感,但是对颜色和空间细节不敏感的那一类细胞)。 低通道数也可以解释为具有较弱的空间语义表达能力,从技术上讲,我们的Fast路径在空间维度上没有特殊的处理,因此由于通道数的减少,其空间建模能力应该低于Slow路径。我们模型的良好结果表明Fast路径削弱其空间建模能力的同时增强其时间建模能力,这是一个理想的tradeoff。 受到这种解释的启发,我们探索了Fast路径中削弱空间容量的不同方法,包括减少输入的空间分辨率、移除彩色信息等。实验结果显示,这些版本也可以取得良好的准确性,这表明了通过削弱空间容量来构建轻量级的Fast路径是有效的。 3.3 Lateral connections 两个路径的信息是学习后才融合在一起的,所以一条路径并不关心另一条路径学习了什么,我们使用横向连接(在two-stream中融合RGB和光流时用过[12,13])来实现这一融合操作。在图像的目标检测任务中,横向连接被广泛应用于融合多尺度空间分辨率特征中。 类似于[12,35],我们在每个阶段“stage”的两个路径之间都附加一条横向连接,特别的,如果是ResNets,这些横向连接紧跟在pool1,res2,res3和res4之后。这两个路径的时间维度不同,所以横向连接会先进行转换来匹配它们(细节见3.4节)。我们使用单向连接来将Fast路径的特征融合到Slow路径中(做了双向连接实验,效果类似)。 最后,对两个路径的输出进行全局平均池化global average pooling,再将两个池化后的特征向量拼接在一起输入到全连接分类器中。 3.4 Instantiations实例化 我们的SlowFast思想是通用的,可以使用不同的backbone来具体实现,这一小节描述一下我们对该网络结构的一个具体实例。 表1指定了一个SlowFast模型的示例子,我们用T×S²来表示时空尺寸,其中T是时间长度,S是方形空间裁剪的宽高,接下来描述具体细节。 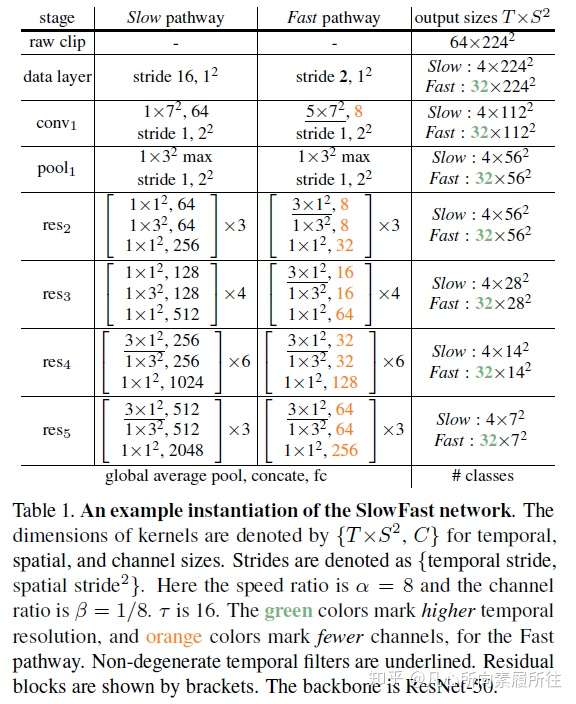 表1. SlowFast模型的一个实例化示例,两个分路的卷积核尺寸 表1. SlowFast模型的一个实例化示例,两个分路的卷积核尺寸Slow pathway。表1中的Slow 路径是一个从[12]修改得到的时域strided 3D ResNet,它的输入帧数为T=4帧(从原始裁剪的64帧中τ=16采样得到的),在这个实例化中我们不采用时域下采样(因为当输入stride较大时,时域下采样会影响效果)。 和典型的C3D/I3D模型不同的是,我们只在res4进而res5的时候使用非退化non-degenerate的时域卷积(时域卷积核尺寸>1,表1中下划线部分);而该路径中从conv1到res3的所有卷积核基本上都是2D卷积。之所以这么做是由实验导向的,我们在实验中发现如果在前几层就使用时域卷积的话会降低精度。我们认为这可能是因为当物体移动速度很快而我们的时域跨度又很大时,除非空间感受野足够大(在后面的层中空间感受野就很大),否则在时间感受野中这些帧几乎没有什么联系。 Fast pathway。表1的这个例子中,Fast路径的α=8(时间分辨率是Slow的8倍,表中绿色),β=1/8(通道数是Slow的1/8,表中橙色)。 Fast路径在每个block中都有非退化的时间卷积,这是因为我们发现这个路径能够保持较好的时间分辨率来捕获详细的运动信息,此外,Fast路径没有专门设计时域下采样层。 Lateral connections。我们的横向连接将Fast的特征融合到Slow路径,不过在融合前需要进行特征尺寸的转换匹配(只能有一个维度尺寸不同)。将Slow路径的特征形状定义为{T,S²,C},Fast路径的特征形状为{αT,S²,βC}。在横向连接中我们尝试了如下的转换方法: (i)Time-to-Channel:我们把Fast的特征reshape成{T,S²,αβC},也就是把所有帧的特征全部放到一帧的通道上。 (ii)Time-strided sampling:我们直接简单在Fast特征的时间维度上进行采样(每α帧采样1帧),即将Fast特征采样成{T,S²,βC}。 (iii)Time-strided convolution:我们使用3D卷积(卷积核5×1²,stride=α,输出通道为2βC)对Fast特征进行卷积,得到形状为{T,S²,2βC}的特征。 最后,Fast路径横向连接的输出被融合到Slow路径中(求和或者拼接)。 4.Experiments:Action Classification 我们使用标准的评估方法在4个视频识别数据集上评估了我们的方法,对于本部分的动作分类实验,我们考虑了被广泛使用的Kinetics-400,最新的Kinetics-600和Charades;对于第5节中的行为检测实验,我们使用具有挑战性的AVA数据集。 训练。我们在 Kinetcis上训练的模型没有使用ImageNet或其他数据集做预训练(from scratch),使用[19]中的同步SGD进行训练,详见附录。 在时域上,我们从完整的视频上随机采样一个片段clip(T×τ帧,这里论文是αT×τ帧,感觉应该是笔误),然后输入到Slow路径和Fast路径的分别是T帧和αT帧;在空域上,我们对原视频或者其水平翻转进行缩放(缩放规则是:随机地从[356,320]中选择一个值作为短边的长度,按比例缩放),然后随机裁剪出224×224大小。 推理。按照惯例,我们会沿着视频的时间轴均匀采样10个片段clips,对于每个clip,我们先按照短边256像素进行比例缩放,然后裁剪3个256×256大小的区域作为输入进行推理,最后我们将3个softmax分数的平均值作为预测结果。 由于现有论文在推理时的时空裁剪策略不同,我们在与这些论文比较推理时间时 公布了每个时空“视图”(一种时域clip,空域crop策略即为一种时空视图)下的FLOPs。因为在我们的案例中,推理时的空间尺寸为256²(而不是训练时的224²),时域上一共有10个clips,且每个clip都有3个空间crops,所以一共有30个时空视图。 数据集。Kinetics-400:约240k训练视频和20k验证集视频,400个人体动作类别;Kinetics-600:约392k训练视频,30k验证视频,600个类别;我们给出了top-1和top-5类别准确度,并给出单个空域中心裁剪clip的计算代价FLOPs;Charades:约9.8k训练视频,1.8k验证视频,157个类别(多标签类别),activities的时间跨度比较长,平均30s,给出了mAP来度量效果。 4.1 Main Results Kinetics-400。表2比较了我们的模型和SOTA方法的结果,我们的SlowFast模型分别使用了不同的输入采样量(T×τ)和不同的backbones(Res50/101[24], Nonlocal[56])。 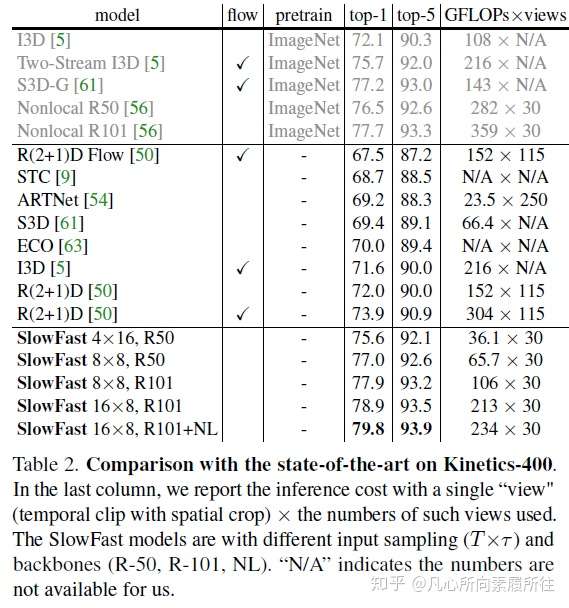 表2. Kinetics-400数据集上的结果 表2. Kinetics-400数据集上的结果如图2所示,对于所有变体,Fast pathway都能以相对较低的成本持续改善Slow路径的性能。 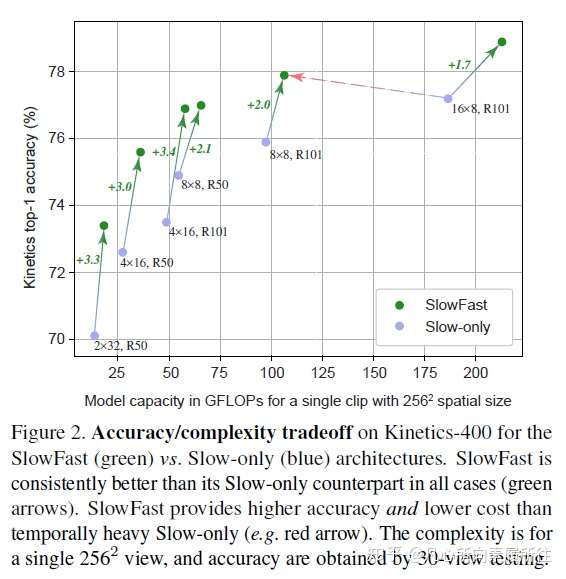 图2.Kinetics-400数据集上的速度/精度trade off,SlowFast和SlowOnly的比较 图2.Kinetics-400数据集上的速度/精度trade off,SlowFast和SlowOnly的比较Kinetics-600。这个数据集是一个相对比较新的,现有的结果也不够好的数据集,所以我们的目标主要是提供一些可供将来参考的结果,如表3所示。 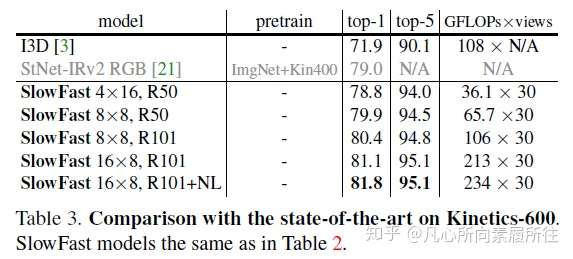 表3. Kinetics-600数据集上的指标 表3. Kinetics-600数据集上的指标Charades。这个数据集的动作持续时间更长,表4展示了我们的SlowFast在该数据集上的结果。  表4. Charades数据集的结果二.论文总结 表4. Charades数据集的结果二.论文总结1.核心思想 视频行为识别需要从视频中提取鲁邦的外观(空间语义)和运动特征来进行行为识别,所谓SlowFast是指采用Slow和Fast两种采样率的path(输入两个path的是视频采样后的帧)来并行处理视频,Slow path以较低的采样率来处理输入视频(2D卷积+3D卷积),提取随时间变化较慢的外观特征,为了提取鲁邦的外观特征,卷积核的空间通道数较大;Fast path以较高的采样率来处理输入视频(3D卷积),提取随时间变化较快的运动特征,为了降低该通道的复杂度,卷积核的空间通道数较小;然后通过横向连接对两个path的特征进行融合,进行行为识别。 作者文中提了一个“可能比较粗糙且为时尚早的类比”,在灵长类动物的视网膜神经细胞中,有80%的细胞以较低的速率工作,它们对视觉运动变化不敏感,但是可以提供良好的空间和颜色细节(这类比为Slow Path中的卷积核来提取外观特征,总参数量占两个通道总参数的80%左右);剩余20%的细胞以较高速率工作,能够敏感地捕捉运动变化(这类比为Fast Path的卷积核来提取运动特征,总参数占20%左右)。 2.模型结构 SlowFast模型结构图如上图所示,其主要的工作流程大致如下所示: step1:用快慢两种速率采样输入视频 step2:采样后的视频帧对应输入到Slow/Fast两个分路 step3:Slow分路使用ResNet 2D Conv + 3D Conv提取视频空间语义特征,size {T,S²,C} step3:同时Fast分支使用ResNet 3D Conv提取视频时域运动特征,size{αT,S²,βC},其中α>1,β<1 step4:横向连接统一两个分路的特征 step5:Softmax进行分类 详细的流程可以看原文和代码~~~~~~~ 3.实验 本文实验相当丰富,还是值得好好看看,学学大佬都是怎么做实验的,实验结果主要是下边几部分: (1)Kinetics-400数据集SOTA (2)Kinetics-600新数据集提供了个baseline结果 (3)Fast分支能以很小的代价提高Slow-Only的精度 (4)AVA行为检测 4.与Two Stream、C3D的区别 (1)与Two Stream方法的区别 对行为识别有一定了解的小伙伴应该知道Two Stream方法采用RGB + Optical flow两个通路来分别提取视频的空间语义特征和运动特征进行行为识别,而本文的SlowFast也是两个通路提取两方面特征进行识别,二者的主要区别有如下几个部分: a:SlowFast更强调两个分路不同的采样和处理速率,这也是SlowFast的核心思想 b:Two Stream两个分路的backbone是相同的,而SlowFast中的Fast分支更轻量级 c:双流是手工设计的特征,无法端到端学习,而SlowFast可以端到端学习两个分路的所有参数 (2)与C3D系列方法的区别 另一种广泛的行为识别方法是C3D及其改进,C3D采用3D卷积同时提取空域和时域特征,SlowFast中虽然也用到了3D卷积,但和C3D行为识别模型是有区别的:
a:C3D模型将2D卷积扩展到时空域,同时处理空域和时域的信息(默认时域和空域是平等的、对称的),而SlowFast采用和TwoStream类似的想法将空域和时域的处理拆分开,这更符合时域和空域特征的关系(二者不应该像一幅图的x,y那样对称处理) b:SlowFast中用到了3D卷积,但又不太相同。Slow通路前几层使用2D卷积,后两层才用3D卷积(实验发现比全用3D卷积效果更好);Fast通路每一层都用的是3D卷积,但是各层维持时域维度大小不变,尽可能地保留时域信息(而C3D中是越深的层时域维度越小)。 三.论文创新提出了快慢采样提取时空特征的idea,采用了TwoStream两分路的结构并使用3D卷积的操作实现该idea,达到了SOTA的行为识别效果。
| 




 发表于 2020-12-1 09:07:53
发表于 2020-12-1 09:07:53
 楼主
楼主