|
时序动作提名生成任务的目的是给未裁剪的长视频生成一定数量的时序动作提名,一个时序提名即是一个可能包含动作片段的时序区间(从开始边界到结束边界),通常采用一定提名数量下的召回率指标来衡量算法效果。我们认为高质量的时序动作提名应该具备几点特质:(1)灵活的时序长度(2)精确的时序边界(3)可靠的置信度分数。现有的基于滑窗或anchor的方法或是基于聚类的方法都不能同时在这几个方面做好。为了解决这几个难点,[2]中提出了边界敏感网路-BSN,下面首先对BSN方法进行简单的回顾。 一、BSN方法回顾关于BSN[2]方法,我之前也写过论文笔记,如果不了解的同学可以先看一下。简单来说,在BSN方法中,我们首先去定位时序动作片段的边界(开始节点和结束节点),再将边界节点直接结合成时序提名,然后对每个候选时序提名,基于动作置信度分数序列来提取一个32维度的proposal-level的特征,最后基于所提取的proposal-level的特征来评估时序提名的置信度。下面对BSN方法的优点和缺点进行一下讨论。 优点: - 框架:提出了一种全新的且非常有效的时序提名生成框架,能够产生满足(1)时长灵活(2)边界准确(3)评分可靠的时序动作提名;
- 灵活性:BSN方法的模块非常简单且灵活,能够灵活地应用于不同的垂类场景。
缺点: - 效率不够高:提名特征提取以及置信度评估的过程是对每个时序提名逐个进行的,虽然可以在一定程度上做并行加速,但总体上还是效率比较差;
- 语义信息丰富性不足:为了保证提名特征提取过程的效率,BSN中所设计的32维提名特征是比较简单的,但也限制了置信度评估模块从特征中获得更加丰富的语义信息;
- 多阶段:BSN方法是一个多阶段的方法,没有将几部分网络联合优化。
为了优化这些缺点,我们所期盼的是在一个统一的网络中同时高效的产生时序概率序列以及所以时序提名的置信度分数,且在这个过程中还要进一步提升语义信息的丰富性。基于anchor的方法(如SSAD[3] )能够通过anchor机制,将大量anchor与特征图相关联,从而可以直接通过卷积层来生成每个anchor的置信度、边界偏移量进行预测。然而,BSN中并没有预定义anchor,而是自底向上地生成更加灵活多变的时序提名,因此anchor机制并不适用。 因此,为了解决BSN方法中所存在的缺陷,我们在这篇论文中提出了一种新的时序提名置信度评估机制-边界匹配机制(Boundary-Matching mechanism, BM mechanism),以及基于边界匹配机制的边界匹配网络(Boundary-Matching Network, BMN): 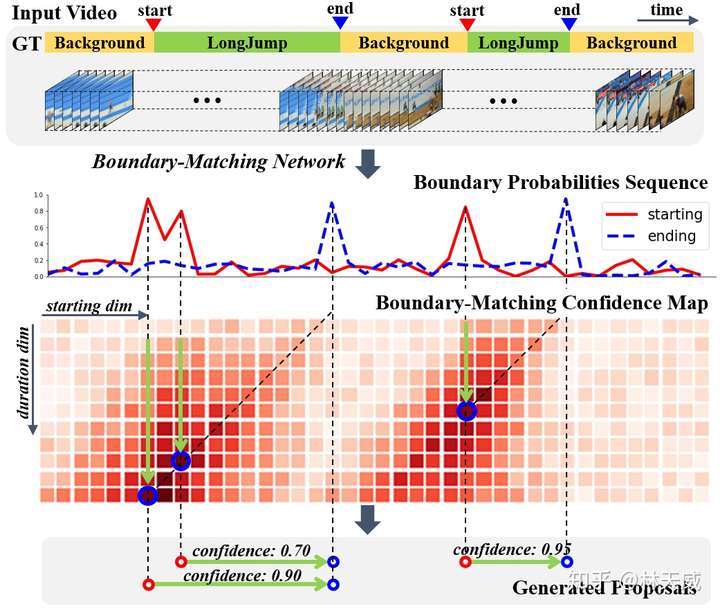 BMN网络能够同时生成与BSN中类似的一维边界概率序列,以及二维的BM置信度图来密集的评估所有可能存在的时序提名的置信度分数。 二、边界匹配机制(Boundary-Matching mechansim)BM置信度图 首先介绍一下什么是BM置信度图。此处,我们将一个时序提名定义为一个开始边界和一个结束边界所构成的边界匹配对。然后我们按照时序提名开始边界的位置以及时序提名的长度将所有可能存在的时序提名结合成一个二维的边界匹配图。如下图所示,在这个图上的每一列上的时序提名具有相同的开始时间,而每一行上的时序提名具有相同的时序长度。此外,由于右下角这个三角形区域中的时序提名的结束时间超出了视频的范围,因此在训练和测试时不被纳入考虑。 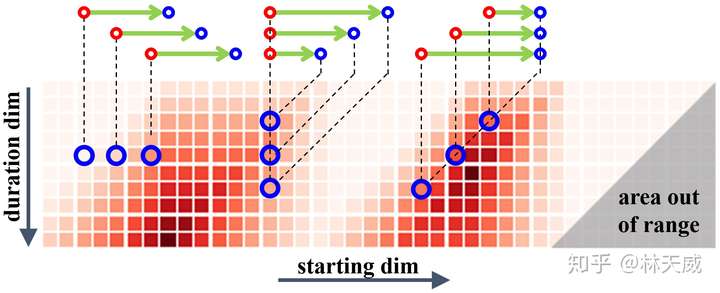 因此,这张二维的边界匹配图就能够表示所有潜在存在的时序提名。而在BM置信度图中,每个点所代表的数值就是其所对应的时序提名的置信度分数。因此,我们可以通过生成BM置信度图来同时给所有时序提名生成置信度分数。我们将BM置信度图记作  ,此处 ,此处  为输入时序特征序列的长度, 为输入时序特征序列的长度,  则为最大的时序提名长度,该值基于数据集来确定。 则为最大的时序提名长度,该值基于数据集来确定。 为了从时序特征序列来生成所需要的BM置信度图,我们需要从时序特征序列先生成BM特征图,再基于BM特征图来生成BM置信度图: 此处,  是时序特征序列的通道数, 是时序特征序列的通道数,  则是每个时序提名的特征采样点数。 则是每个时序提名的特征采样点数。 BM特征图的生成 首先介绍从时序特征序列到BM特征图的生成过程,这也是这篇文章的核心部分。具体而言,对于  大小的边界匹配图上的任意一个时序提名 大小的边界匹配图上的任意一个时序提名  ,要在其时序范围内,从时序特征序列中采样 个点,构成 ,要在其时序范围内,从时序特征序列中采样 个点,构成  作为该提名的特征。我们希望这个采样过程是准确且高效的,即所有提名的特征采样过程是同时完成的。我们所提出的方法如下: 作为该提名的特征。我们希望这个采样过程是准确且高效的,即所有提名的特征采样过程是同时完成的。我们所提出的方法如下: 对于时序提名 ,我们在其扩展的时序范围  内采样N个点,构造一个采样矩阵 内采样N个点,构造一个采样矩阵  。其中,对于第n个采样点 。其中,对于第n个采样点  , 对应的 , 对应的 定义为: 定义为: 然后,我们在时序维度上对时序特征序列  和 进行点乘,从而得到 : 和 进行点乘,从而得到 : 可以看出,这实际上是一个通过点乘来实现线性插值的过程,下图更形象地表示这个过程: 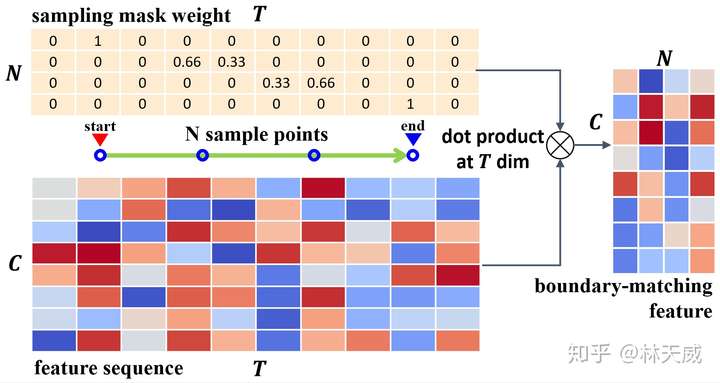 最后,通过将采样矩阵从 扩展到  ,并进行 ,并进行  和 和  在时序维度上的点乘,即可以得到BM特征图 在时序维度上的点乘,即可以得到BM特征图  。因此,通过矩阵点乘的方式,我们可以非常高效地同时给所有时序提名生成准确对应的特征表示。此外,直接从特征序列中采样得到的提名特征表示比起从一维概率序列中采样得到的概率序列具有更丰富的语义信息。 。因此,通过矩阵点乘的方式,我们可以非常高效地同时给所有时序提名生成准确对应的特征表示。此外,直接从特征序列中采样得到的提名特征表示比起从一维概率序列中采样得到的概率序列具有更丰富的语义信息。 在论文中,我们将这个从时序特征序列采样得到BM特征图的过程记作BM layer。 从BM特征图生成BM置信度图 这个过程即  。此处我们采用了3D卷积层来消除采样维度 ,再通过几个2D卷积层来生成最终的结果。此处的2D卷积实质上是获得了每个时序提名 周围几个提名的context信息,丰富了时序提名的context信息。 。此处我们采用了3D卷积层来消除采样维度 ,再通过几个2D卷积层来生成最终的结果。此处的2D卷积实质上是获得了每个时序提名 周围几个提名的context信息,丰富了时序提名的context信息。 BM置信度图的训练方式 在训练中,我们采用BM标签图  来作为BM置信度图的监督,此处 来作为BM置信度图的监督,此处  是对应时序提名与真值之间的最大IoU重叠度。为了达到更好的效果,训练中我们生成了两种BM置信度图,分别采用回归损失和加权二分类损失训练,记作 是对应时序提名与真值之间的最大IoU重叠度。为了达到更好的效果,训练中我们生成了两种BM置信度图,分别采用回归损失和加权二分类损失训练,记作  和 和  。下面给出ActivityNet-1.3数据集验证集上的一个可视化结果作为示例,可以看出两种置信度分数存在一定互补性,在测试时取两者的乘积作为最终的置信度分数。 。下面给出ActivityNet-1.3数据集验证集上的一个可视化结果作为示例,可以看出两种置信度分数存在一定互补性,在测试时取两者的乘积作为最终的置信度分数。 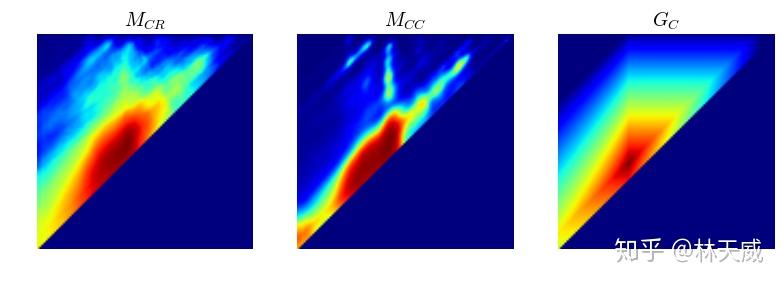 三、边界匹配网络(Boundary-Matching Network) 三、边界匹配网络(Boundary-Matching Network)基于我们所提出的边界匹配机制,我们提出了边界匹配网络BMN,整个方法的框架如下图一所示,网络具体的结构则如下表所示。 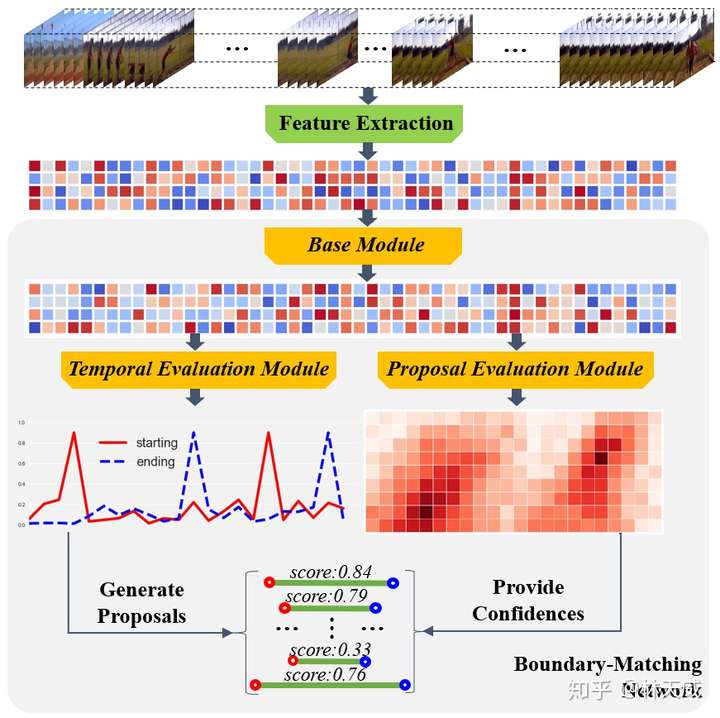 BMN网络结构图 BMN网络结构图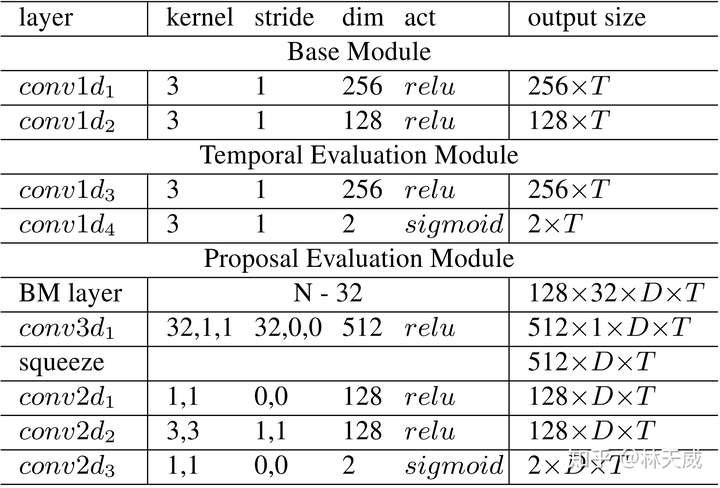 BMN网络配置表 BMN网络配置表可以看出,BMN主要包括3个模块。基础模块包括两个1维卷积层,其作用是作为backbone,处理输入的特征序列,并输出被后续两个模块所共享的时序特征序列。时序评估模块包含两个1d卷积层,输出开始概率序列和结束概率序列,用于后续的提名生成。提名评估模块,则包含了前面所介绍的BM layer,一个3d卷积层以及3个2d卷积层,最终输出为BM置信度图。 采用该网络生成时序边界概率序列后,我们采用与BSN中相同的方式产生候选时序提名,并从同时生成的二维置信度图中取出时序提名对应的置信度分数用于最后的时序提名排序。最后,我们同样采用了Soft-NMS方法来去除了冗余结果。 四、实验BMN方法在THUMOS-14和ActivityNet-1.3数据集上都获得了明显的效果提升,这里就不详细介绍了。此处主要介绍一下BMN和BSN的对比实验。 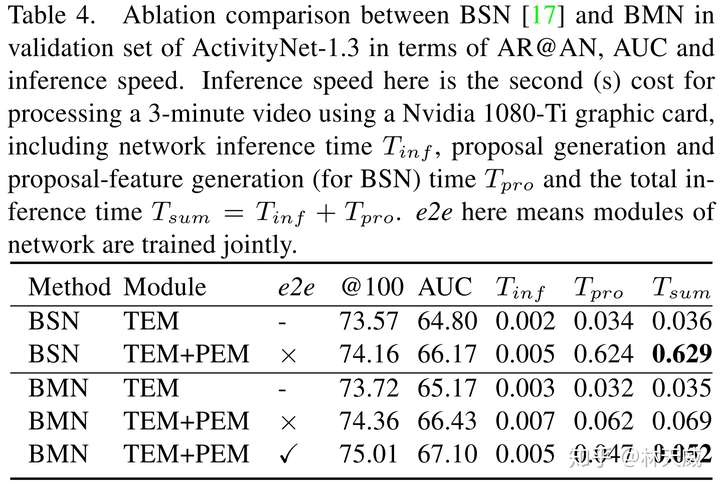 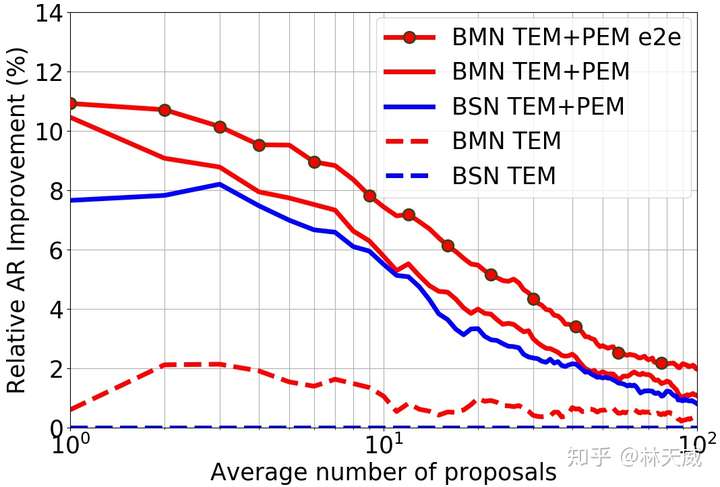 Ablation comparison between BSN and BMN in terms of relative AR improvement (%) vs AN curve on validation set of ActivityNet-1.3, where relative AR improvement is calculated based on BSN-TEM results. Ablation comparison between BSN and BMN in terms of relative AR improvement (%) vs AN curve on validation set of ActivityNet-1.3, where relative AR improvement is calculated based on BSN-TEM results.主要从性能表现和算法效率上讲一下对比实验的结论: - 性能:BMN中的提名评估模块在单独训练的情况下也要比BSN中的提名评估模块效果好;
- 性能:BMN中联合训练两个模块能带来显著的性能提升;
- 效率:BSN算法在inference时大部分时间都耗费在了提名特征构造的过程中了;
- 效率:BMN通过非常高效的提名特征采样,效率上比BSN有非常明显的提升。
五、讨论本文的主要贡献是通过引入一种全新的时序提名评估机制以及高效的特征采样方式,来提升了BSN方法的性能和效率。这个采样方式之所以高效,是因为每次前向时采样矩阵是不变的,因此可以预先计算得到,实质上算是用空间换时间吧。另外,我们在论文中所构建的BMN模型其实是非常简单的,在网络设计和优化方面还存在着不小的提高空间,欢迎大家基于BMN方法再做改进,我们将尽快开源基于PaddlePaddle的代码。 题外话:因为忙和自己的惰性,专栏也好久没有更新了,希望之后自己能努力保持一定的更新,一方面通过输出的方式读论文能够加深自己对论文的理解,另外一方面写作表达能力、把问题讲清楚的能力真的很重要,只能多写多练。最后,我们部门在图像和视频相关的各个主要研究方向上基本都有一定投入和相关业务,欢迎感兴趣的应届校招同学发简历到 lintianwei01@baidu.com 参加内推。 参考文献[1] T. Lin, X. Liu, X. Li, et al. BMN: Boundary-Matching Network for Temporal Action Proposal Generation. arXiv preprint arXiv:1907.09702, 2019. [2] T. Lin, X. Zhao, and S. Haisheng. Bsn: Boundary sensitive network for temporal action proposal generation. In Euro- pean Conference on Computer Vision, 2018. [3] T. Lin, X. Zhao, and Z. Shou. Single shot temporal action detection. In Proceedings of the 2017 ACM on Multimedia Conference, pages 988–996. ACM, 2017.
| 




 发表于 2020-12-1 09:06:38
发表于 2020-12-1 09:06:38
 楼主
楼主