|
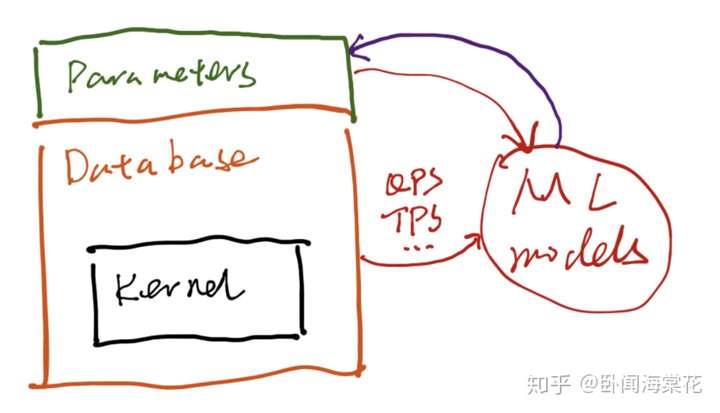
简要讨论两种将机器学习方法(ML)用于优化 OLTP 数据库内核的方式。 第一种方式是将数据库内核与使用 ML 算法的模块分立,将数据库暴露出来的配置参数与性能数据输入到 ML 模块中,常见应用有自动调节参数、异常检测等。以自动调参为例,这种分立式的应用方式给出的参数建议可以对标资深 DBA 根据业务运维经验和对数据库内核的理解给出的参数配置。
这种 ML 与数据库内核松耦合的方式便于将两者分别开发、迭代和维护,ML 可以作为增值服务单独上线与售卖,且对数据库内核的稳定性影响较小。对于开发者来说,算法工程师相对而言可以了解较少的数据库内核运转机制,跨界感较弱,上手快,但仍需要理解数据库参数的物理意义,从而能够出设计出合理的训练数据集和训练任务。不过,算法很难和资深 DBA 在处理异常情况、给出解释并沉淀出运维方案等方面进行有效竞争。 第二种方式是将 ML 算法深度融入进数据库内核,用户不需要感知 ML 的运转,只需要买一份数据库服务就享受到 ML 带来的便利(if any) ,常见应用有 learned index, learned query optimizer, learned cache prefetcher, etc. 这种方式对开发者的要求更高。首先,开发者需要寻找并定义出一个 ML 可以发力去解决的实际问题,这一步要求开发者对数据库的实际应用和内核的运转机制了如指掌;其次,开发者要能够设计出一套合理的数据接口和控制接口,从复杂的内核运转状态中抽取出最有价值的信息作为训练数据与模型输入,也需要寻找到可以最大化 ML 效用的工作平面;最重要的是,开发者不可避免地要对 ML 落入内核进行工程优化,降低其对内核性能和稳定性带来的影响,要知道稳定性对于数据库来说是特别重要的。 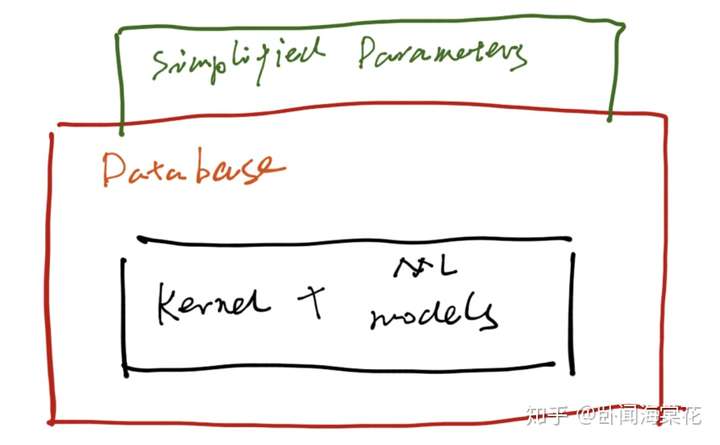 方式二:数据库内核与 ML 算法深度融合 方式二:数据库内核与 ML 算法深度融合在这条路子上,阿里云数据库联合北京大学邹磊老师团队形式化地定义出了数据库内核(LSM-tree 存储引擎)中由于后台异步数据合并任务造成的大面积缓存失效问题(Cache Invalidation Problem),率先探索出了使用 ML 算法预测一个 compaction 任务在执行过程中和刚刚结束执行时,数据库上层 SQL 负载可能会访问到数据记录并提前将其加载进 cache 中,从而实现降低 cache miss,提高 QPS 稳定性的目的。我们慎重选择了“主键范围”作为数据库负载、存储引擎内核状态和 ML 模型之间的数据接口,巧妙设计了 ML 对 cache 替换的控制接口,取得了良好的 ML 算法效果。不可或缺的,我们在工程上做了一系列优化,降低 ML 算法对内核带来的额外开销。相关结果发表在了数据库顶会 VLDB 2020 的 Research Track 中,已经面世
| 



 发表于 2020-11-12 16:04:53
发表于 2020-11-12 16:04:53