|
DVQA是腾讯多媒体实验室设计的基于深度学习的全参考视频质量评估算法。在整个视频链路中,我们可以量化大部分模块,如采集,上传,预处理,转码,分发。我们最未知的却恰恰是最关键的部分,即用户的视频观看体验。DVQA适用于在源参考视频可用的场景下,精确衡量视频内容的人眼感知质量。 DVQA包含多个质量评估算法模型,本次开源的算法为C3DVQA。本项目使用Python开发,深度学习模块使用PyTorch。代码使用模块化设计,方便集成较新的深度学习技术,灵活的自定义模型,训练和测试新的数据集。 算法设计 C3DVQA所使用的网络结构如下图所示。其输入为损伤视频和残差视频。网络包含两层二维卷积来逐帧提取空域特征。级联后使用四层三维卷积层来学习时空联合特征。三维卷积输出描述了视频的时空掩盖效应,我们使用它来模拟人眼对视频残差的感知情况:掩盖效应弱的地方,残差更容易被感知;掩盖效应强的地方,复杂的背景更能掩盖画面失真。 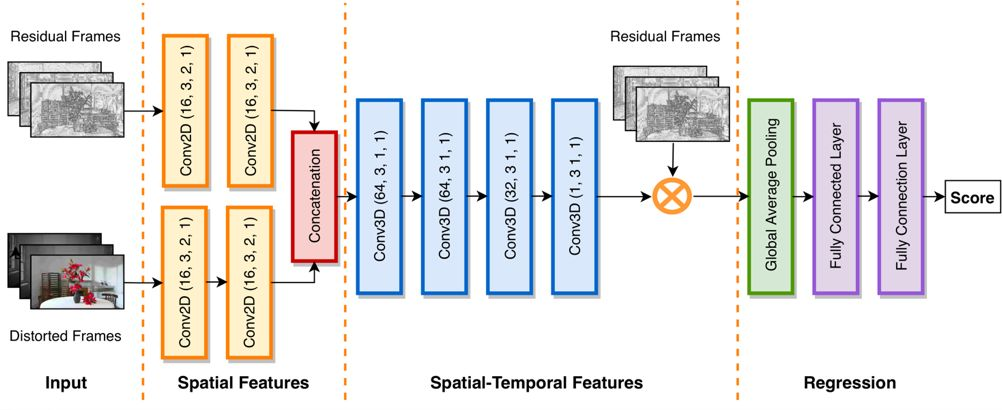
网络最后是池化层和全连接层。池化层的输入为残差帧经掩盖效应处理后的结果,它代表了人眼可感知残差。全连接层学习整体感知质量和目标质量分数区间的非线性回归关系。 评测效果 我们在LIVE和CSIQ两个视频质量数据集上对所提出算法的性能进行验证。并使用标准的PLCC和SROCC作为质量准则来比较不同算法的性能。我们所提出的C3DVQA与常用的全参考质量评估算法进行了对比,包括PSNR,MOVIE,ST-MAD,VMAF和DeepVQA,结果如下表所示。 方法 | PLCC (LIVE) | SROCC (LIVE) | PLCC (CSIQ) | SROCC (CSIQ) | PSNR | 0.7271 | 0.7398 | 0.5988 | 0.6106 | MOVIE | 0.8609 | 0.8481 | 0.6295 | 0.6247 | ST-MAD | 0.8570 | 0.8386 | 0.7674 | 0.7766 | VMAF | 0.8115 | 0.8163 | 0.6570 | 0.6377 | DeepVQA | 0.8952 | 0.9152 | 0.9135 | 0.9123 | C3DVQA | 0.9122 | 0.9261 | 0.9043 | 0.9152 |
(LIVE和CSIQ两个数据库上不同全参考算法性能比较) 真诚开源 我们希望DVQA能够帮助解决视频感知质量评估的业务痛点,无论是使用现有模型还是使用自己的数据库来训练新模型。我们也欢迎任何形式的协同开发,不管是贡献数据库,还是贡献预训练模型,甚至是抛出业务场景中所遇到的问题。下一步计划中,我们会: 进一步优化算法性能,降低复杂度 更详细的benchmark 拓展算法至UGC视频场景
如果你对这个算法感到兴趣,还请给这个项目一个 Star,欢迎提出你的 issue 和 PR!
DVQA 正式开源! https://github.com/Tencent/DVQA
| 




 发表于 2020-5-23 09:57:40
发表于 2020-5-23 09:57:40
