本帖最后由 马猴烧酒 于 2018-8-27 08:45 编辑
本文转载于https://blog.csdn.net/u010167269/article/details/52717394
1 简介
图1-1
图1-2
对于 Open Image dataset 中的 validation set,Google 对上面的这些 labels 进行了人工的检验,将错误的 labels 剔除掉了。每一张图像大约有 8 个 labels,示例如下:
图1-3
这个 Open Image 由 Google、CMU、Cornell 大学合作完成,这个 Open Image 数据集,以及最近放出的 Youtube-8M 对机器学习界又是一次助攻。 2 数据集内容 图片数据集中有两个描述数据集的csv文件,分别是image.csv,label.csv,在csv中每一张图像被赋予一个唯一的 64-bit 的标识码(ID),image.csv和label.csv由这唯一id联系起来 数据集被分为 training set,包含 9011219 张图像,validation set,包含 167057 张图像。每一张图像包含 0 个,1 个或者多个 image-level 的 labels。 数据集太过庞大,提供了image.csv和label.csv来指定地址 images.csv 文件格式 给的原图像地址文件格式,每一行包含了原图像 URL 地址,它们对应唯一的 ImageID、标题、作者,以及 license 信息: - 000060e3121c7305,”https://c1.staticflickr.com/5/4129/5215831864_46f356962f_o.jpg“,\
- “https://www.flickr.com/photos/brokentaco/5215831864“,\
- “https://creativecommons.org/licenses/by/2.0/“,\
- “https://www.flickr.com/people/brokentaco/“,”David”,”28 Nov 2010 Our new house.”
打开看看,如下:
图2-1
labels.csv 文件格式 首先,labels 各自对应的单词含义,在 词典 dict.csv 里描述如下:
图2-2
标注 annotation 的格式如下:ImageID, confidence: labels, confidence: labels, ……,下面分别是 train、validation 的 csv 文件:
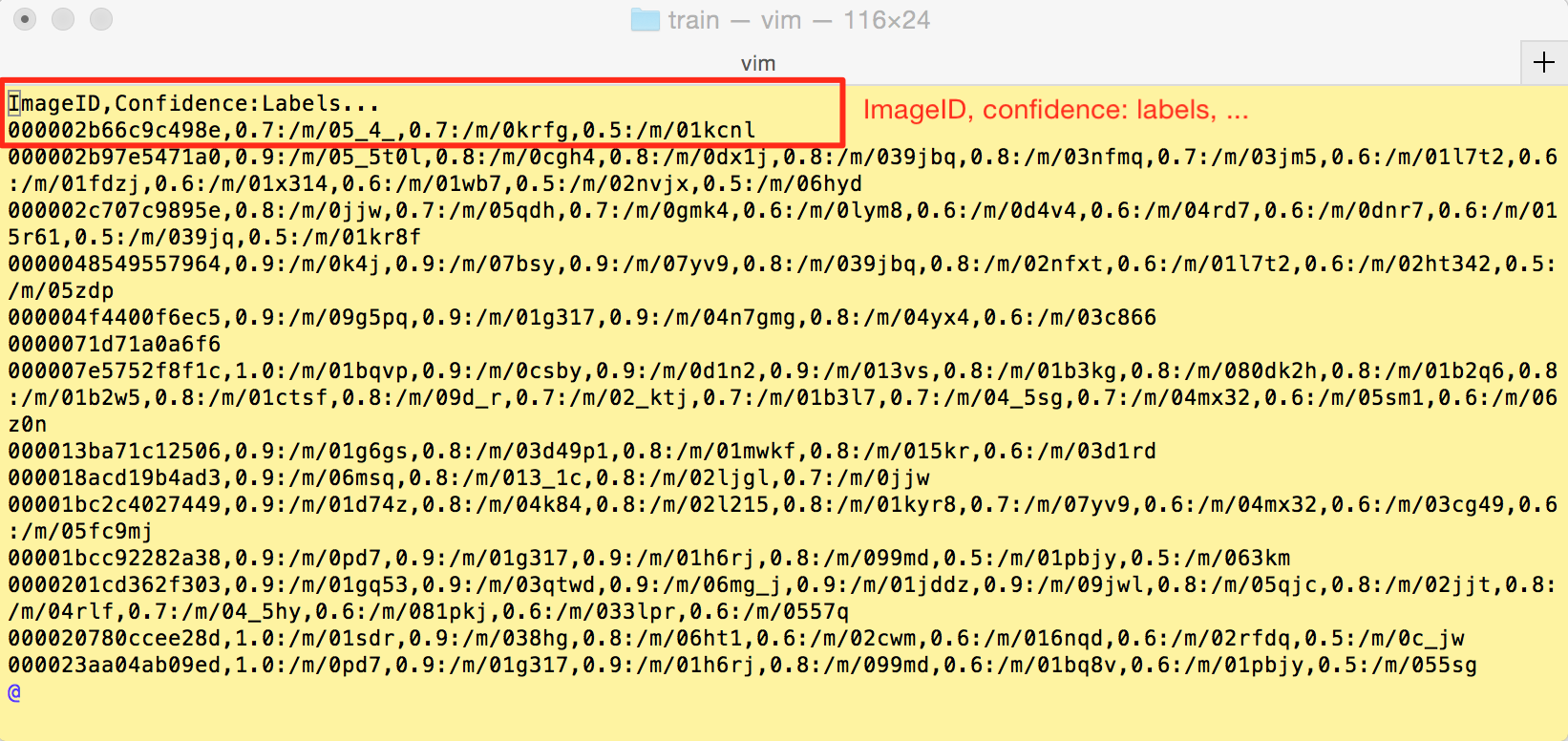
图2-3
对于人工检验的 confidence 而言,其值只有两个取值:1和0,给定的 csv 文件如下: 可以看到,人工验证过的中的 ImageID 与 机器标注中的 ImageID 一样,但是 confidence 只1和0两个值。 Open Image 数据中,各类是非常不均衡的。有些 label 对应着百万张图像,有些 label 只有几百、几十张图像:
图2-5
同时,机器标注中,也包含了一些噪声,通常来说,label 对应的图像越多,这个 label 越准确。
图2-6
下载链接:
| 




 发表于 2018-8-24 17:38:06
发表于 2018-8-24 17:38:06













