|
分类是机器学习中比较常见的任务,对于分类任务常见的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC曲线(Receiver Operating Characteristic Curve)等。
这篇文章将结合sklearn对准确率、精确率、召回率、F1 score进行讲解,ROC曲线可以参考我的这篇文章:sklearn ROC曲线使用。
混淆矩阵
如上图所示,要了解各个评价指标,首先需要知道混淆矩阵,混淆矩阵中的P表示Positive,即正例或者阳性,N表示Negative,即负例或者阴性。
表中FP表示实际为负但被预测为正的样本数量,TN表示实际为负被预测为负的样本的数量,TP表示实际为正被预测为正的样本数量,FN表示实际为正但被预测为负的样本的数量。
另外,TP+FP=P’表示所有被预测为正的样本数量,同理FN+TN为所有被预测为负的样本数量,TP+FN为实际为正的样本数量,FP+TN为实际为负的样本数量。
准确率结合上面的混淆矩阵,公式还可以这样写: 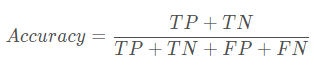
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
下面我们看一下sklearn中计算准确率的示例:
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred)) # 0.5
print(accuracy_score(y_true, y_pred, normalize=False)) # 2
# 在具有二元标签指示符的多标签分类案例中
print(accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2))))
| 



 发表于 2020-5-13 08:32:38
发表于 2020-5-13 08:32:38
 楼主
楼主