|
这是一篇关于时序动作定位的文章(ICCV2019),原文的作者TianweiLin已经在知乎上对自己的文章进行了详细的分析。但这篇文章个人觉得很不错,我这里虽然不再具体详细的分析。但也简单的记录一下,也为自己阅读留下点痕迹。很羡慕作者能在自己的研究基础上不断的深入研究,直至走到这个方向的最前沿。这篇文章也是冠军方案。视频动作定位与动作识别肯定是相辅相成的两个兄弟领域。以前一直有个好奇的点,究竟是先定位再识别,还是先识别出物体,再去定位。从目前检测算法来看,都是产生proposal,再去识别分类,对应着前者,而人类似乎对应着后者的方式。 [color=inherit !important][backcolor=rgba(247, 247, 247, 0.882)]林天威:[ICCV 2019][时序动作提名] 边界匹配网络详解zhuanlan.zhihu.com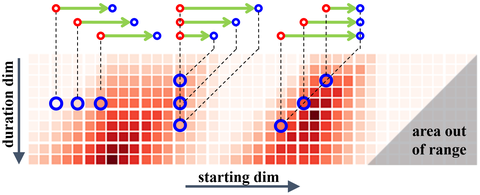 本文所研究的内容就是Temporal action proposal generation。传统的一些方法可以产生很好的边界,但是无法产生很好的置信区间。BMN算法就可以做到二者的得兼。与之对比的BSN(Boundary-Sensitive Network)方法,这也是作者ECCV2018的文章,是对每一个边界匹配区间进行一次置信度的计算。带来了一些问题,主要就是在计算效率上低,特征过于简单,以及网络的多个模块之间不是一个统一的框架。 以上,作者提出Boundary-Matching mechanism,在这篇文章中,本文的主要的核心就是一张map的建立,这个map就像是字典一样,是一个全局的统一的一张map。就可以解决上述的效率问题。本文的效率更多的是以空间换时间的思路。然儿在BSN的中,每一个confidence是单独计算的,有些计算是重复的,因此,在本文中,以矩阵的方式进行计算,实现整体置信度的计算。  图1 Overview of our BMN 图1 Overview of our BMN图1显示的BMN算法的概要,核心就是对于一段视频,同时产生'边界概率序列'和'边界匹配置信度'。在这个confidence map中,其纵坐标duration dim是根据数据集人为确定的一个action时长的最长部分。但实际上有些视频不是很长,所以在下方的一些点就是颜色很浅,在中间部分颜色很深。横坐标代表着起始点,纵坐标代表着持续的时长。当我第一次看到这里的时候,彷佛感觉中间的边界概率的结果与最后的置信度的结果是对应的,似乎可以相互转换的,但实际上,这两个结果在原文中特意强调了是同步生成的。其实最后的置信度区间是基于每个点的位置开始是等概率的,而概率序列决定了不同的开始概率,因此,最终的一个置信度结果是要将这个两个结果的一个融合。更加像是一个条件概率的形式。 Approach直接将核心的步骤一步一步的阐述清楚记录下就可以了。 Feature Encoding 双流网络在大多数数据的分类效果上取得了优秀的效果,作者用双流网络产生视频的特征。(虽然知道一个分支是RGB输入,但不知道另一个分支的输入是什么,等着开源吧。猜测大概率是flow吧)。 Boundary-Matching Mechanism  表示proposal 表示proposal  的置信度 的置信度 表示特征map 表示特征map 表示特征序列 表示特征序列Boundary-Matching Layer 我们需要求的是  ,而我们已知的拥有的是是在上述的双流网络提取的特征。BM layer实现的就是中间桥梁 ,而我们已知的拥有的是是在上述的双流网络提取的特征。BM layer实现的就是中间桥梁  的构建,N是在一段视频中的采样点个数。 的构建,N是在一段视频中的采样点个数。 即需要  这样的转换。 这样的转换。 重点谈一下weight项   图2 BM layer 图2 BM layer首先这N个采样点在[start,end]区间进行均匀的采样,构成一张掩码的权重,构造方式就是: 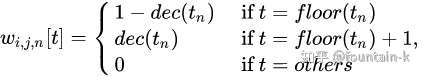 仔细一下的意思就是如果取得的位置不是整数点,取其左右的两个整数点。这里的权重究竟对应什么呢?其实本质上就是特征的一个加权。作者为什么要构造这个矩阵,是本文的核心。如图2所示,最终这个结果就是一个NxC的矩阵,可以假设想象一个,如果每个点的位置都恰好为整数,既图2左上的sampling mask weight 中的每一行只会存在一个1,其余的均为0。那么这样的相乘得到的结果不就是随机选取的位置对应的N个特征。但如果不是整数,其就会是一个加权的特征。采样点的特征就是如上图的  。(或者说是K=2的最近邻),而之后矩阵的一个扩张其实就是一个并行计算的过程,可以加快计算。因此作者在原文中这样说: 。(或者说是K=2的最近邻),而之后矩阵的一个扩张其实就是一个并行计算的过程,可以加快计算。因此作者在原文中这样说: BM feature map contains rich feature and temporal context for each proposal, and gives the potential for exploiting context of adjacent proposals. 个人觉得这一部分就是本文最核心的地方,本人对为什么矩阵这样乘的一点小小见解。虽然在数学上就是一堆矩阵计算的过程,但是应该思考下为什么要这样成。这里是构造了相邻接两个帧,或者也可以把构造mask的方式改为四个的加权,或其他方式如特征置换。 Score Fusion 最终将边界概率与置信度做一个相乘作为最终的预测概率值。并不是直接拿 最终将边界概率与置信度做一个相乘作为最终的预测概率值。并不是直接拿  作为最终的结果。 作为最终的结果。Training of BMN loss就是一些不同的loss在一起的一个加权,主要由两部分组成: 当然作者还加了一个  正则化项。 正则化项。 Conclusion本文是一篇思路很清晰的文章,是一篇效率至上的文章,这与企业research的风格相符合。高效率是存在很多可以直接并行计算的模块,减少计算,准确率的提升可能在于密集采样产生更好的特征来提高置信度。给自己放的假一下子就结束了,第一次打卡了上海。时间真的是匆匆。愉快的日子总是那么短暂,又要开学了。
| 




 发表于 2020-12-1 09:05:53
发表于 2020-12-1 09:05:53
 楼主
楼主